
Data Base
- DBMS(Data Base Management System)
- RDB, NoSQL
- RDB(관계형 데이터베이스): MySQL, Oracle, Ms-SQL, SQLite
- NoSQL(Not Only SQL): Redis, Hbase, mongo DB
- DELETE vs TRUNCATE vs DROP
- DELETE: 데이터(ROW)만 삭제(따라서 1,2 삭제후 새로운 데이터 넣을때 다시 1,2id 지급)
- TRUNCATE: ROW도 삭제하는데 메타데이터도 삭제(1,2삭제후 데이터 넣을때 3,4id 지급)
- DROP: 완전히 테이블 자체를 삭제
- DML, DDL, DCL 차이도 알아두면 좋음
- DML(Data Manipulation Language): CRUD(Create, Read, Update, Delete)
- DDL(Data Definition Language): Create, Alter, Drop, Truncate
- DCL(Data Control Language): Grant, Revoke
- 표를 잘기억해야함 특히 용도와 속도, 권한 등
- DML, DDL, DCL 차이도 알아두면 좋음

정규화
메모리 남김없이 얼마나 효율적으로 저장할 수 있을까, 테이블 구조를 얼마나 깔끔하게 많들 수 있을까에서 나온 조건들의 성립
- 1NF: 모든 도메인은 원자 값으로 구성
- 쉼표로 여러개의 데이터를 저장하지말고 한 컬럼에는 하나의 데이터만 들어가자1
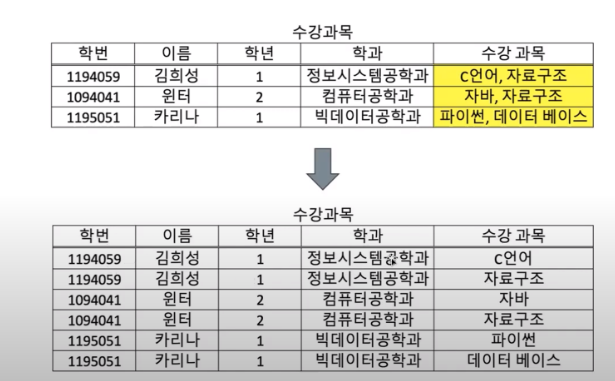
- 2NF: 부분 함수 종속성 제거(기본키에 종속적인 데이터 분리)

- 3NF: (기본키가 아닌 모든 속성에서) 이행적 함수 종속(A→B→C)제거

- 부가 설명: 만일 과목하나당 사용하는 강의실이 하나로 정해져있다면 2개의 테이블로 나눠서 설명할 수 있다.
- 과목코드에는 과목명, 학점, 강의실이 포함되어있다.
- 강의실은 위치, 컴퓨터 유무, 최대인원이 포함되어있다.
- log를 통해서 기존 테이블에서 데이터를 계속해서 나눈 새로운 테이블들에 데이터를 옮기고 그 이후 기존 테이블을 삭제한다.
Transaction/Isolation
Transaction
- 정의
- 논리적인 작업 셋
- 트랜잭션은 필요한 범위 내에서 최소화 하는 것이 바람직함
- ACID
- Atomictioy(원자성): 성공하면 Commit, 중간에 에러가뜨면 아예 Rollback
- Consistency(일관성): 제약조건에 위배되지 않으면서 데이터 변경되어야함
- Isolation(격리성): 각각의 트랜잭션은 격리가 된상태로 진행해야함(만일 한개의 트랜잭션이 다른 트랜잭션에 영향을 미친다면 잠궈야함)
- Durability(영속성): 성공한 데이터 변경은 영구적으로 적용해야함
- 트랜잭션의 필요성
- 트랜잭션이 없다면, 데이터를 되돌리는 것을 전부 try-catch문 Code로 구현해야함 ⇒ 트랜잭션 쓰면 이런 예외처리없이 Rollback, commit이면 해결이 됨
Isolation(격리수준)
- 여러 트랜잭션이 동시에 처리될때, 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게(수정할 수 있게) 허용할지 말지 결정하는 것
- 종류
- READ UNCOMMITTED
- DIRTY READ: COMMIT 되지않은 데이터를 읽음
- READ COMMITED
- NON-REPEATABLE READ
- 하나의 트랜잭션에서 동일한 SELECT 쿼리에 대해 다른 결과를 가져옴
- 한마디로 데이터 수정하고 COMMIT안하면 SELECT시 변경 데이터 적용안됨
- REPEATBALE READ
- PHANTOM READ: SELECT문1 - INSERT문 - SELECT for update 문2 이렇게 있다면 SELECT문 1과 2의 값이 다름, 그걸 PHANTOM READ라고함 → COMMIT하면 둘다 동일해짐
- SERIALIZABLE
- 위 3개와 달리 속도가 많이 느려짐 → 락을 많이 걸기때문이다.
- READ UNCOMMITTED
Performance
Index(인덱스)
- 왜 인덱스에 B-Tree를 사용할까? B-Tree vs HashTable
- Hash는 Range Scan(부등호 <,> 검색이 불가능하고 Like 검색도 인덱스를 사용할 수 없다.(ex. Hash는 key 1이면 50, 2이면 30 이런식인데 1≤ a ≤30이런식으로 찾는다하면 일일히 찾아야해서 불가능함
- 왜 B-Tree를 사용할까? BST vs B-Tree
- 상당수의 DBMS에서 Index구현에 B-Tree를 사용하는 이유는 저장매체의 특성때문이다.
- RDB는 아직까지도 상당 부분 HDD에 데이터를 저장함.
- HDD는 순차 읽기 성능은 준수하지만 Random Access는 상대적으로 느리다. 따라서 In-Memory가 아닌 디스크(HDD)에 데이터가 저장된 상황에서는 상대적으로 Random Access가 적고, CUD에 Overheard가 적은 B-Tree가 BST보다 성능이 더 좋다.
- Primary Key, Unique Key 역시 B-Tree 등으로 인덱싱 되어있다.
- 가능한 Index는 변경이 별로 안걸리는(데이터가 별로 변경이 없는) 컬럼에 생성하는 것이 좋다.
- Where절과 정확히 일치하는 인덱스가 있어도 Optimizer의 선택에 의해 다른 인덱스를 선택 할 수 있다.
Execution Plan(실행 계획)
- Optimizer가 수행할 Query를 분석하여, 비용기반, 혹은 규칙 기반으로 최적의 Query 수행방법을 찾는다
Scale up/ Scale out
- Scale up
- 수직정 향상, CPU&RAN 저장 장치등을 변경하여 성능을 높임
- Scale out에 비하여 쉽다
- 물리적 한계가 존재(현존하는 최고등급의 CPU,RAM이 결국 한계이다.)
- Scale out
- 수평적 Scale 향상
- 서버의 를 늘려서 성능을 높임
- Scale up에 비하여 구조가 복잡해진다
- Scale up에 비하여 물리적 한계까 적다.(가능하다면 서버의 수를 계속 늘리면 되기때문이다.)
- Repication과 Sharding
- Replication(복제), 복제된 서버를 레플리카라고함
- Sharding 여러 데이터 베이스 서버에 분산 저장하는것
NoSQL(Not Only SQL)
- 정의: 일반적으로 R-DB의 Query에 사용하는 SQL이 아닌 다른 Query방식을 사용하는 DBMS의 통칭
- Key-Value쌍으로 데이터 저장
- JSON과 유사한 형태로 데이터 저장
- Column-Based(컬럼 기반)데이터 저장
- 기존 R-DB와 유사한 형태로 데이터 저장
No SQL을 사용하는 이유
- 유연성: 스키마 선언 없이 필드의 추가 및 삭제가 자유로운 Schema-less구조
- 확장성: 스케일 아웃에 의한 서버 확장이 용이하다
- 고성능: 대용량 데이터를 처리하는 성능이 뛰어나다
- 가용성: 여러 대의 백업 서버 구성이 가능하여 장애 발생 시에도 무중단 서비스가 가능하다
단점
- 데이터베이스 일관성에 약하다. 이 일관성을 가용성, 속도로 바꿔서 빠르다고 봐야한다.
- key값에 대한 입출력만 지원한다.
- 스키마가 정해져 있지 않아, 데이터에 대한 규격화가 되어있지 않다.
- 데이터 중복으로 인한 수정 작업의 번거로움이 있다.
출처
- 조르디 강의 4주차 DB
RDBMS의 한계와 NOSQL사용이유(https://sujl95.tistory.com/83)
'데이터베이스' 카테고리의 다른 글
| [DB]AWS RDS를 이용한 MySQL 서버 생성 (0) | 2024.12.15 |
|---|---|
| RDBMS의 구조 (0) | 2024.08.12 |