
그룹 함수
데이터분석 개요
- 세가지 함수
- AGGREGATE FUNCTION: COUNT, SUM, AVG, MAX, MIN 등 각종 집계함수가 포함된다
- GROUP FUNCTION: 결산개념(소개, 중계, 합계), SQL테이블 한번 읽는것으로 원하는값 찾는다
- WINDOW FUNCTION: 분석함수, 순위함수가 여기에 포함된다
- ROLLUP
- 계층적 요약, 특정 열 또는 집합에 대한 총합 및 소계 계산한다
- 예시(쿼리문과 결과문)
SELECT OrderDate, Product, SUM(Amount) AS TotalAmount
FROM OrderTable
GROUP BY ROLLUP(OrderDate, Product);--------------------------------
| OrderDate | Product | TotalAmount |
--------------------------------
| 2023-01-01 | Product A | 100 |
| 2023-01-01 | Product B | 150 |
| 2023-01-01 | NULL | 250 |
| 2023-01-02 | Product A | 200 |
| 2023-01-02 | Product B | 120 |
| 2023-01-02 | Product C | 80 |
| 2023-01-02 | NULL | 400 |
| NULL | NULL | 650 |
--------------------------------
- GROUPING
- 소계면 1반환 아니면 0반환한다
- 예시(쿼리문과 결과문)
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);DNAME GROUPING(DNAME) JOB GROUPING(JOB) Total Empl Total Sal
SALES 0 CLERK 0 1 950
SALES 0 MANAGER 0 1 2850
SALES 0 SALESMAN 0 4 5600
SALES 0 NULL 1 6 9400
RESEARCH 0 CLERK 0 2 1900
RESEARCH 0 ANALYST 0 2 6000
RESEARCH 0 MANAGER 0 1 2975
RESEARCH 0 NULL 1 5 10875
ACCOUNTING 0 CLERK 0 1 1300
ACCOUNTING 0 MANAGER 0 1 2450
ACCOUNTING 0 PRESIDENT 0 1 5000
ACCOUNTING 0 NULL 1 3 8750
NULL 1 NULL 1 14 29025
- CUBE
- 결합 가능한 모든 갓에 대하여 다차원 집계 생성한다
- 사용할 경우 내부적으로 GROUPING COLUMNS 순서 바꿔서 또 쿼리 추가 수행한다
즉 가능한 모든 조합에 subtotal포함해서 시간이 많이걸린다 - 예시
SELECT DNAME, JOB, MGR, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB, MGR);DNAME JOB MGR Total Sal
-----------------------------------------------
SALES Clerk 7698 800
SALES Clerk NULL 800
SALES Manager 7698 1600
SALES Manager NULL 1600
SALES Salesman 7698 2850
SALES Salesman NULL 2850
SALES NULL NULL 5250
RESEARCH Clerk 7788 1100
RESEARCH Clerk NULL 1100
RESEARCH Analyst 7566 6000
RESEARCH Analyst NULL 6000
RESEARCH Manager 7839 2975
RESEARCH Manager NULL 2975
RESEARCH NULL NULL 10075
...
NULL NULL NULL 49550
- GROUPING SETS
- 더욱더 다양한 소계집합이다, 쉽게 얘개하면 GROUP BY <필드1> UNION ALL GROUP BY <필드2>
이런문장을 GROUP BY GROUPING SETS(필드1, 필드2) 로 한번에 가능하다 - 예시
- 더욱더 다양한 소계집합이다, 쉽게 얘개하면 GROUP BY <필드1> UNION ALL GROUP BY <필드2>
-- 부서별, JOB 별 인원수와 급여 합을 구한다.
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);DNAME JOB Total Empl Total Sal
---------------------------------------------------
ACCOUNTING All Jobs 3 8750
RESEARCH All Jobs 5 10875
SALES All Jobs 6 9400
All Departments Clerk 4 4150
All Departments Salesman 4 5600
All Departments President 1 5000
All Departments Manager 3 8275
All Departments Analyst 2 6000
윈도우 함수
- 윈도우 함수
- 기존 데이터베이스에서 칼럼과 칼럼간의 연산, 비교, 연결은 쉬웠지만 행과 행(인스턴스와 인스턴스)의 비교 연산은 어려웠다 -> WINDOW FUNCTION의 등장(행과 행 쉽게 처리 가능)
- 윈도우 FUNCTION 종류
- 순위 관련 함수: RANK, DENSE_RANK, ROW_NUMBER 함수
- 집계 관련 함수: SUM, MAX, MIN, AVG, COUNT함수
- 그룹내 순서 관련함수: FIRST_VAULE, LAST_VALUE, LAG, LEAD함수
- 비율관련 함수: CUME_DIST, PERCENT_RANK, NTLE, RATIO_TO_REPORT
- 통계 관련 함수: CORR, COVAR_POP, COVAR_SAMP, STDDEV, VARIANCE, REGR등(ORACLE 통계 관련 함수)
- OVER 문구 필수적
- SELECT WINDOW_FUNCTION(ARGUMENTS)OVER({PARTITION BY 칼럼}{ORDER BY 절} )(WINDOWING 절)) FROM 테이블명;
- 참고로 OVER절 내 ORDER BY는 SQQL SERVER에서 지원안한다
- 그룹 내 순위 함수
- RANK: 순위 구하기
- DENSE_RANK: 동일한 순위-> 하나의 건수(EX. 원래면 RANK 함수는 1 2 2 4 등인게 1 2 2 3등 처리된다)
- ROW_NUMBER: 공동순위X -> 고유한 순위를 부여한다(ORDER BY 까지 해줘야 기준있는 고유순위 부여가 된다)
- 일반 집계 함수
- SUM: 파티션별 윈도우의 합이다
- MAX: 파티션별 윈도우의 최댓값이다
- MIN: 파티션별 윈도우의 최솟값이다
- AVG: 파티션별 조건에 맞는 평균값이다
- COUNT: 파티션별 조건에 맞는 개수이다
- 그룹 내 행 순서 함수(SQL SERVER 지원 안한다)
- FIRST_VALUE: 파티셔녈 조건에 부합하는 윈도우에서 가장 먼저 나온값, 공통처리 안하기때문에 ORDER BY 절 사용권장한다
- LAST_VALUE: 파티션별 윈도우에서 가장 나중에 나온값, 공통처리 안하기때문에 ORDER BY 절 사용권장한다
- LAG: 파티셔녈 이전 몇번째 행값 가져오기, 3개의 ARGUMENTS 사용가능, 두 번째인자는 몇번째
앞의 행 가져올지 결정(DEFAULT 1), 세번째는 데이터가 NULL인 경우 다른 값 바꿔서 가져올 수 있다 - LEAD: 파티션별 이후 몇번째 행값 가져오기
- 그룹 내 비율함수(SQL SERVER 지원 안한다)
- RATIO_TO_REPORT함수: SUM 칼럼값의 백분율 소수점으로 구한다
- ex. 1200/5600 값이 소수로 들어감
- PERCENT_RANK: 파티션 기준 제일 먼저 나오는 값 0, 마지막갓 1로 순서별 백분율 나타낸다
- ex. 구간이 5개면 0, 0.2, 0.4, 0.6 0.8, 1
- CUME_DIST: 누적백분율을 구한다
- ex. 구간이 4개면 0, 0.2, 0.4, 0.6, 0.8, 1
- NTILE: N등분한 결과 구하기
- ex. SELECT NTILE(4) OVER~ //정렬 후 4개 그룹으로 분류화
- RATIO_TO_REPORT함수: SUM 칼럼값의 백분율 소수점으로 구한다
DCL
유저 생성 및 권한 제어
- 권한 부여: GRANT
- 권한 회수: REVOKE
Oracle 제공

SQL server 로그인 2가지 방식
1. windows 인증 방식: windows 로그인한 정보 -> SQL server에 접속한다(훨씬 더 안전), 두 연결을 트러스트된 연결이라고 함
2. 혼합 모드 방식(windows 인증 또는 SQL인증), Oracle 인증과 같은 방식: 아이디와 비번
유저 생성과 시스템 권한 부여
- 시스템 권한 약 100개 이상 -> 일일히 권한 부여하지 않고 ROLE을 이용하여 쉽게 권한 부여한다
- Oracle 예시: SYSTEM 유저가 grant SCOTT 유저 하게되면 SCOTT 유저는 유저 생성권한까지 부여받는다
grant 유저 create 유저 또는 table 등, 권한 선택 후 부여가능하다
object에 대한 권한 부여
- 특정 테이블, 뷰 등에 대한 SELECT, INSERT, DELETE, UPDATE 작업 명령어 권한부여(오브젝트 권한은 4개 권한을 따로 관리한다
ROLE을 이용한 권한 부여
- 많은 유저가 생기면 한명이 여러명의 유저에게 여러개의 권한 부여 쉽지 않다
그렇다보니 몇가지 권한을 넣어둔 ROLE을 생성하고 유저에게 ROLE을 부여한다 - 많이 사용되는 ROLE 2가지: CONNECT, RESOURCE 로 Oracle에서 사용한다
두 항목에서 부여하는 권한이 많아서 여기선 따로 언급하지않겠다 - 유저 삭제와 작업물 삭제
- DROP과 CASCADE 명렁어를 통해 사용자 삭제와 사용자가 만든 오브젝트를 삭제 시킬 수 있다 추가로 사용자가
다른 유저에게 준 권한까지도 삭제 가능하다
ex. DROP USER JISUNG CASCADE //JISUNG이 만든 오브젝트 삭제 및 유저 삭제
- DROP과 CASCADE 명렁어를 통해 사용자 삭제와 사용자가 만든 오브젝트를 삭제 시킬 수 있다 추가로 사용자가
- SQL server ROLE
- SQL Server 에서는 Oracle의 ROLE처럼 생성하는 방법과 다르게 기본적으로 제공되는 ROLE멤버로 참여하는 방식으로 사용된다.
- 서버 수준 역할명과, 데이터 베이스 수준 역할명이 있는데 역할명이 곧 행동을 나타낼만큼 이해가 쉽다.
서버 수준 역할명의 대표적인 것으로는 public, dbcreator, securityadmin등이 있고 데이터베이스 수준 역할명의 대표적인 것은 db_datareader, db_owner, db_accessadmin 등이 있다. - 각 요구에 맞게 2개를 적절히 주면된다
- 인스턴스 요구 사용자 > 서버 수준 역할 부여
- 데이터 베이스 수준 요구 사용자 -> 데베 수준역할 부여
절차형 SQL
절차 지향적인 프로그램이 가능하도록 제공한다. 종류는 다음과 같다
PL, SQL(Oracle), SQL/PL(DB2), T-SQL(SQL Server)
PL/SQL 개요(Oracle)
- 특징: Blcok 구조, Block내에 DML문장, QUERY 문장, 그리고 IF, LOOP 등 사용한다
절차적 프로그래밍을 가능하게 하는 트랜잭션 언어이다 - Oracle 저장 모듈: Procedure, User Defined Function, Trigger
- 블록 구조

T-SQL 문법(SQL Server)
- Stored Procedure과 사용목적은 다르지만 기본 문법은 비슷하다
- 4가지 유형의 파라미터(@ parameter)
- VARYING: 결과 집합이 출력 매개변수로 사용되도록 지정한다
- DEFAULT: 지정된 매개변수 호출없을시, 기본값으로 처리한다
- OUT또는 OUTPUT: 처리된 결과값을 EXECUTE문 호출시 반환한다
- READONLY: 프로시저 본문 내에서 매개변수 업데이트 및 수정 불가능하다
- WITH 옵션에 저장할 수 있는 옵션
- RECOMPILE: 프로시저의 계획을 런타임에 캐시하지않고 컴파일한다
- ENCRYPTION: 프로시저 원본 텍스트를 알아보기 어려운 형식으로 반환한다
- EXECUTE AS: 프로시저를 실행할 보안 컨텍스트 지정한다
Procedure 생성과 활용
- 과정을 알아야한다(아래 사진 참고)
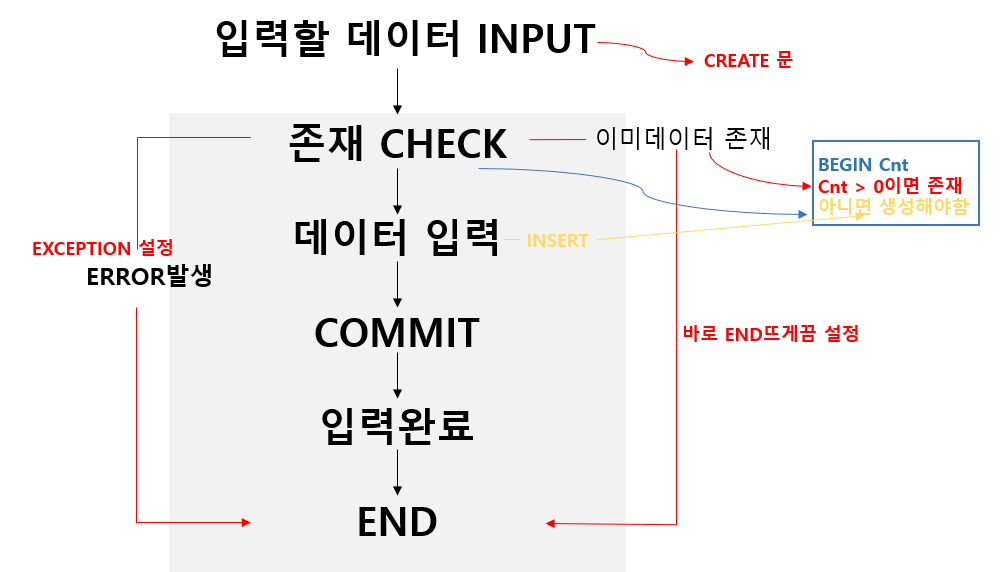
User Defined Function의 생성과 활용
데이터 베이스 내에 저장되는 절차형 SQL 명령문, RETURN 값 필요하다

- 다른점
- TYPE선언과 값지정 추가 부분
- 함수 호출부분에서 SQL Server는 dbo.<함수명> 으로 호출한다
Trigger의 생성과 활용
DML문이 수행될때, 데이터베이스에서 자동 동작(사용자 호출X)
- 트리거 절차
- 트리거 선언(CREATE TRIGER문 사용)
- 필요한 변수 선언, 신규로 입력된 데이터 저장(Oracle: 'new', SQL server: 'insert')
- 한 테이블을 기준으로 다른 테이블 업데이트한다
- 업데이트 결과가 없다면 새로운 레코드 입력한다
- 트리거 장점
- 데이터 베이스의 보안 강화해준다
- 잘못된 트랜잭션 예방시켜준다
- 업무 규칙 자동적용해준다
참고
'데이터베이스 > SQL' 카테고리의 다른 글
| [SQL] SQLD 50회 후기 및 문제유형 (4) | 2023.09.15 |
|---|---|
| [SQL] SQL 활용(1) (0) | 2023.08.08 |
| [SQL] 기본 정리 (2) | 2023.07.31 |
| [SQL]데이터 모델과 성능 (0) | 2023.07.24 |
| [SQL] 데이터 모델링의 이해 (1) | 2023.07.17 |